Swish and Mish
The Swish function in PyTorch would be:
def swish(x):
return x * F.sigmoid(x)
The Mish function in PyTorch would be:
def mish(x):
return x * torch.tanh(F.softplus(x))
For both of these functions smoothness plays a beneficial role in optimization and generalization and they achieve a bit better results than ReLU in general.
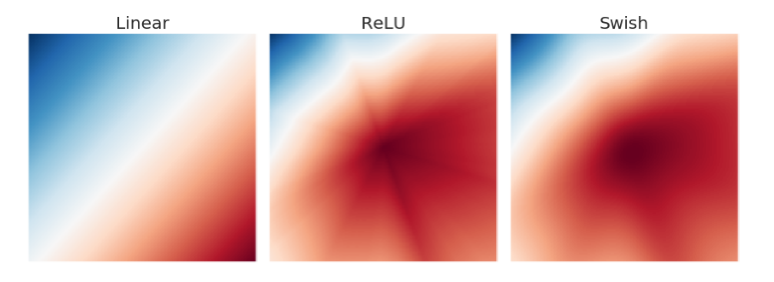
The figure is from the Swish paper, generated by passing two scalars, the x and y into a randomly initialized neural network that outputs a single scalar (the color value).
The ReLU network output landscape has distinctive sharp regions of similar magnitudes whereas the Swish network output landscape is more smooth.
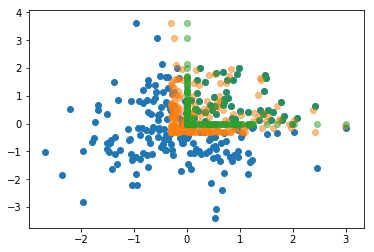
It may be interesting to compare the regions of data distribution after passing randomly generated normal distributed input to ReLU and Mish in this case.
t = torch.randn(222,222)
plt.scatter(t[0], t[1]) #blue
m = mish(t)
plt.scatter(m[0], m[1], alpha=0.5) #orange
r = F.relu(t)
plt.scatter(r[0], r[1], alpha=0.5) #green